![وی پی ان ⭐ VPN ▷▷ [لینک مستقیم] :](https://parksmalayer.ir/wp-content/uploads/2021/10/vpn_app.jpg)
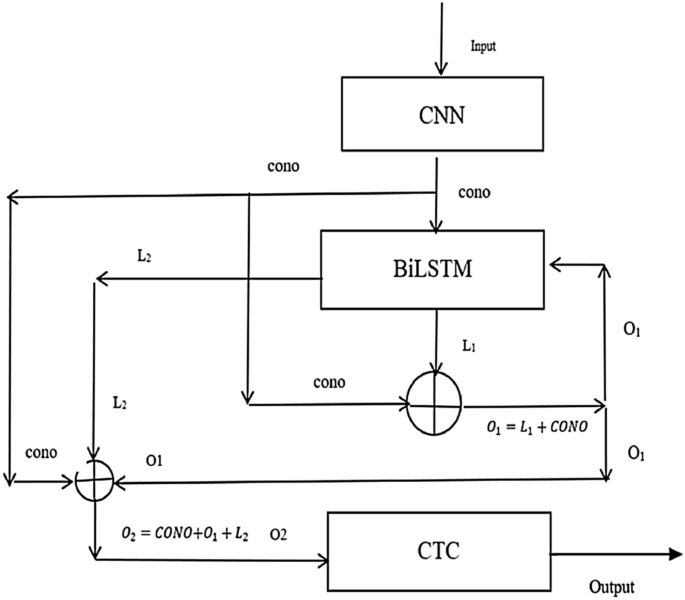
روش پیشنهادی از دو بخش تشکیل شده است: (الف) ساختار شبکه CRNN-RES و اصلاحات لایه RNN، (ب) اصلاحات لایه پیچشی. نمای کلی ساختار در شکل 1 نشان داده شده است. شکل 1  نمودار معماری خلاصه لایه RNN در شبکه CRNN-RES. ساختار شبکه CRNN-RES و تغییرات لایه RNN شبکه کلی ساختار CRNN1 از سه بخش تشکیل شده است: لایه پیچشی، لایه RNN و لایه رونویسی. از قسمت RNN CRNN-RES در شکل 1، می توانیم ببینیم که لایه RNN CRNN-RES به طور قابل توجهی با لایه RNN CRNN متفاوت است. در آموزش، آموزش بازگشتی برخی از پارامترهای شبکه می تواند اثر شبکه را بهبود بخشد و مقدار پارامترها کمتر از روی هم قرار دادن مستقیم ماژول های شبکه دو لایه است. از آنجایی که شبکه اصلی CRNN از دو لایه BiLSTM استفاده می کند، هدف ما کاهش پارامترهای کلی شبکه و اطمینان از تأثیر شبکه است. به طور خاص، ما BiLSTM لایه RNN را در CRNN بهبود میدهیم. ما BiLSTM را از دو لایه به یک لایه تغییر می دهیم و بلوک شبکه تک لایه BiLSTM را به روش بازگشتی چرخه ای آموزش می دهیم. بخش RNN از ساختار شبکه ارائه شده در این مقاله به شرح زیر معرفی می شود: ما از BiLSTM2,3 به عنوان شبکه اصلی لایه RNN استفاده می کنیم. BiLSTM یک شبکه LSTM دو طرفه است، LSTM سنتی فقط می تواند وابستگی ویژگی های یک طرفه دنباله تصویر را یاد بگیرد، اما دنباله ای که ما تشخیص می دهیم ممکن است وابستگی معکوس داشته باشد، مانند کلمات "google"، "brother"، ما. می تواند کلمات “google” و “brother” را بر اساس “googl” و “brothe” پیش بینی کند، یا کلمات “google” و “brother” را بر اساس “oogle” و “rother” پیش بینی کند. بنابراین در اینجا ما LSTM دو طرفه را به عنوان شبکه اصلی در ماژول RNN CRNN-RES انتخاب می کنیم. ما از استراتژی آموزشی بازگشتی استفاده می کنیم، به طور خاص، CRNN-RES یک اتصال اتصال کوتاه بین خروجی لایه پیچشی و خروجی اضافه می کند. لایه BiLSTM، و نتیجه اولین خروجی به عنوان بخشی از ورودی BiLSTM گرفته می شود. فرآیند مشخص به شرح زیر است: ابتدا CONO (خروجی شبکه در لایه کانولوشن) در لایه BiLSTM و سپس L1 (نتیجه خروجی لایه BiLSTM) و CONO (نتیجه خروجی لایه کانولوشن) قرار می گیرد. ) برای به دست آوردن نتیجه اضافه می شوند که در اینجا با O1 نشان داده می شود. فرآیند خاص را می توان به صورت زیر بیان کرد:$$begin{aligned} O_1 = L_1 + CONO end{aligned}$$
نمودار معماری خلاصه لایه RNN در شبکه CRNN-RES. ساختار شبکه CRNN-RES و تغییرات لایه RNN شبکه کلی ساختار CRNN1 از سه بخش تشکیل شده است: لایه پیچشی، لایه RNN و لایه رونویسی. از قسمت RNN CRNN-RES در شکل 1، می توانیم ببینیم که لایه RNN CRNN-RES به طور قابل توجهی با لایه RNN CRNN متفاوت است. در آموزش، آموزش بازگشتی برخی از پارامترهای شبکه می تواند اثر شبکه را بهبود بخشد و مقدار پارامترها کمتر از روی هم قرار دادن مستقیم ماژول های شبکه دو لایه است. از آنجایی که شبکه اصلی CRNN از دو لایه BiLSTM استفاده می کند، هدف ما کاهش پارامترهای کلی شبکه و اطمینان از تأثیر شبکه است. به طور خاص، ما BiLSTM لایه RNN را در CRNN بهبود میدهیم. ما BiLSTM را از دو لایه به یک لایه تغییر می دهیم و بلوک شبکه تک لایه BiLSTM را به روش بازگشتی چرخه ای آموزش می دهیم. بخش RNN از ساختار شبکه ارائه شده در این مقاله به شرح زیر معرفی می شود: ما از BiLSTM2,3 به عنوان شبکه اصلی لایه RNN استفاده می کنیم. BiLSTM یک شبکه LSTM دو طرفه است، LSTM سنتی فقط می تواند وابستگی ویژگی های یک طرفه دنباله تصویر را یاد بگیرد، اما دنباله ای که ما تشخیص می دهیم ممکن است وابستگی معکوس داشته باشد، مانند کلمات "google"، "brother"، ما. می تواند کلمات “google” و “brother” را بر اساس “googl” و “brothe” پیش بینی کند، یا کلمات “google” و “brother” را بر اساس “oogle” و “rother” پیش بینی کند. بنابراین در اینجا ما LSTM دو طرفه را به عنوان شبکه اصلی در ماژول RNN CRNN-RES انتخاب می کنیم. ما از استراتژی آموزشی بازگشتی استفاده می کنیم، به طور خاص، CRNN-RES یک اتصال اتصال کوتاه بین خروجی لایه پیچشی و خروجی اضافه می کند. لایه BiLSTM، و نتیجه اولین خروجی به عنوان بخشی از ورودی BiLSTM گرفته می شود. فرآیند مشخص به شرح زیر است: ابتدا CONO (خروجی شبکه در لایه کانولوشن) در لایه BiLSTM و سپس L1 (نتیجه خروجی لایه BiLSTM) و CONO (نتیجه خروجی لایه کانولوشن) قرار می گیرد. ) برای به دست آوردن نتیجه اضافه می شوند که در اینجا با O1 نشان داده می شود. فرآیند خاص را می توان به صورت زیر بیان کرد:$$begin{aligned} O_1 = L_1 + CONO end{aligned}$$
(1)
سپس (O_1) را در BiLSTM وارد می کنیم و (L_2) (نتیجه لایه دوم BiLSTM) به (O_1)[اضافهمیشود و CONO (خروجی لایه کانولوشن) و در نهایت (O_2) (خروجی نهایی لایه RNN) به دست می آید که به صورت زیر بیان می شود:$$ شروع{تراز} O_2 = O_1 + L_2 + CONO end{تراز شده}$$
(2)
فرآیند در شکل 1 نشان داده شده است. خروجی لایه کانولوشن با CONO و تابع عملیات BiLSTM با F نشان داده شده است، سپس عملیات اول و دوم را می توان به صورت زیر بیان کرد:$$begin {aligned} left{ begin{array}{lr} O_1= CONO +F(CONO)\ O_2 = F(O_1) +CONO +O_1 end{آرایه} راست. end{aligned}$$
(3)
فرآیند خاص لایه RNN به این صورت است: ما داده هایی را که شکل [timestep, batchSize, 512] دارند ابتدا به BiLSTM وارد می کنیم و یک داده خروجی به شکل [timestep, batchSize, 512] دریافت می کنیم. سپس خروجی قبلی BiLSTM را به خروجی لایه کانولوشن اضافه می کنیم و شکل خروجی [timestep, batchSize, 512] می شود. نتیجه خروجی قبلی دوباره به BiLSTM وارد می شود، شکل ورودی داده ها [timestep, batchSize, 512]، شکل خروجی [timestep, batchSize, 512] است. سپس نتایج عملیات دوم BiLSTM به دو خروجی قبلی اضافه می شود و سپس بعد خروجی داده ها اضافه می شود. توسط لایه اتصال کامل تغییر می کند. شکل نهایی خروجی ([timestep * batchSize, nclass]) است، در نهایت خروجی را تبدیل می کنیم، شکل خروجی نهایی [timestep, batchSize, nclass] است. در اینجا timestep به طول سری های زمانی، batchSize به تعداد هر دسته از تصاویر ورودی به شبکه در طول آموزش و nclass به تعداد دسته بندی اشاره دارد. نظریه ریاضی لایه RNNبرای شبکه های CRNN-RES، محاسبه اصل همان LSTM3 یا BiLSTM است. برای اینکه شرح اصل محاسبه مختصرتر و راحت تر برای خوانندگان قابل درک باشد، ما فقط فرم LSTM یک طرفه را محاسبه می کنیم. تمامی محاسبات ریاضی بر اساس معماری شبکه زیر است. همانطور که در شکل. 2 نشان داده شده است. (w_f * [h_{t-1},x_t] + b_f) end{aligned}$$
(4)
در میان آنها، (w_f) وزن را نشان میدهد، (b_f) نشاندهنده عبارت بایاس، (h_{t-1})[04]9 خروجی آخرین واحد پنهان lstm است، (x_t) ورودی واحد عصبی پنهان فعلی است و ما از sigmoid به عنوان تابع فعال سازی استفاده می کنیم. 2) اطلاعات دروازه حافظه را محاسبه کنید. :$$begin{aligned} i_{1t} = sigmoid(w_i[h_{t-1},x_t] + b_i) end{aligned}$$
(5)
در میان آنها، (w_i) وزن را نشان میدهد، (b_i) نشاندهنده عبارت بایاس است. (h_{t-1}) خروجی آخرین واحد پنهان lstm است، (x_t) ورودی واحد عصبی پنهان فعلی است، و ما از sigmoid به عنوان تابع فعالسازی استفاده کنید.$$begin{aligned} C_{1t} = tanh(w_c[h_{t-1},x_t] + b_c) end{aligned}$$
(6)
در میان آنها، (w_c) وزن را نشان می دهد، (b_c) بیانگر عبارت بایاس است. 3) حالت واحد عصبی را در لحظه فعلی محاسبه کنید:$ $begin{aligned} C_{1t} = C_{1t-1} * f_{1t} + i_{1t} *C_{1t} end{aligned}$$
(7)
جایی که (C_{1t-1}) نشان دهنده وضعیت سلول در لحظه قبل است.4) اطلاعات دروازه خروجی را محاسبه کنید:$$begin{aligned} O_{ 1t} = سیگموئید (w_o[h_{t-1},x_t] + b_o) end{aligned}$$
(8)
در میان آنها، (w_o) وزن را نشان می دهد، (b_o) بیانگر عبارت بایاس است. 5) وضعیت فعلی لایه پنهان فعلی را محاسبه می کند:$ $begin{aligned} H_t = O_{1t} * tanh(C_{1t}) end{aligned}$$
(9)
جایی که (C_{1t}) وضعیت سلول را در لحظه فعلی نشان میدهد. در این زمان، محاسبه واحد LSTM تکمیل شد.6) سپس، محاسبات زیر را انجام دهید:$$begin{aligned} خروجی1 = x_t + h_t end{aligned}$$
(10)
جایی که (x_t) ورودی واحد عصبی لایه پنهان فعلی است، (h_t) خروجی واحد پنهان فعلی lstm است. خروجی 1 را دوباره به واحد lstm وارد کنید. سپس عبارتند از:$$begin{aligned} left{ begin{array}{lr} f_{1t} = sigmoid(w_f * [h_{t-1},output1] + b_f)\ i_{1t} = sigmoid( w_i[h_{t-1},output1] + b_i)\ C_{1t} = tanh(w_c[h_{t-1},output1] + b_c)\ C_{1t} = C_{1t-1} * f_{1t} + i_{1t} *C_{1t }\ O_{1t} = sigmoid(w_o[h_{t-1},output1] + b_o)\ H_t = O_{1t} * tanh(C_{1t})\ output2 = x_t + h_t end{آرایه} راست. end{aligned}$$
(11)
خروجی نهایی به شرح زیر است:$$begin{تراز شده} خروجی = x_t +output2 +output1 end{aligned}$$
(12)
لایه همگرایی انعطاف پذیر CNN و RNN در CRNN، رویکرد کلی این است که مستقیماً ویژگی های خروجی لایه CNN را پس از تبدیل ابعادی به لایه RNN وارد می کند. ما فرض می کنیم که شکل داده های ورودی شبکه [8,1,32,128] است، و 8 به عنوان 8 تصویر برای هر دسته، 1 به عنوان تصویر 1 کانال خاکستری، 32 به عنوان عرض تصویر و 128 نمایش داده می شود. یعنی ارتفاع تصویر سپس بعد از لایه CNN CRNN، شکل ویژگی خروجی [8,512,1,16] است. در این زمان، روش CRNN این است که ویژگی را به یک ویژگی شکل [16,8,512] تبدیل می کند، و سپس ویژگی هایی با طول دنباله 16 را در لایه RNN وارد می کند. در این تنظیمات، دو مشکل وجود دارد: (الف) اگر حداکثر طول کاراکتر در همه عکسها 2 باشد و هر تصویر حداکثر دارای 2 کاراکتر باشد که باید شناسایی شوند، ویژگیها نیز به 16 دنباله تقسیم میشوند و به لایه RNN، اما در واقع، ما فقط به دو دنباله برای پیش بینی کافی نیاز داریم. تغذیه 16 دنباله بدون شک پارامترهای شبکه RNN را افزایش می دهد. در عمل ما به 16 سکانس نیاز نداریم، فقط دو سکانس کافی است. توالی های زیاد دقت و سرعت همگرایی شبکه را کاهش می دهد. (ب) اگر حداقل طول کاراکتر در همه تصاویر 17 باشد و هر تصویر حداقل دارای 17 کاراکتر باشد که باید شناسایی شوند، ویژگی ها نیز به دو دسته تقسیم می شوند. 16 دنباله و به لایه RNN ارسال می شود و شبکه در نهایت دقت هر دنباله را دریافت می کند. این حداکثر طول نتیجه تشخیص تصویر فعلی فقط 16 کاراکتر است، به این معنی که نرخ تشخیص شبکه در این زمان همیشه 0 خواهد بود و هرگز همگرا نخواهد شد. شکل 3 نمودار معماری دقیق لایه RNN در شبکه CRNN-RES. به منظور حل مشکلات فوق، ساختاری طراحی کردیم که می تواند به طور انعطاف پذیر طول توالی داده های ورودی لایه RNN را برای داده های هدف مختلف پیکربندی کند. لایه اتصال انعطاف پذیر بین لایه CNN و RNN، ما آن را لایه CRFC می نامیم و ساختار آن به صورت پویا بر اساس ویژگی های خروجی لایه CNN تنظیم می شود. برای مواردی که طول دنباله کاراکتر هدف بسیار کوچکتر از عرض ویژگی خروجی است، ساختار آن در شکل 3 نشان داده شده است. فرآیند خاص به شرح زیر است: (الف) ویژگی های خروجی توسط لایه CNN هستند. به عملیات های ادغام و کاملا متصل تغذیه می شود، عرض W ویژگی به T تبدیل می شود و این دو اضافه می شوند. ما از K برای نشان دادن اندازه هسته لایه ادغام، S برای نشان دادن اندازه گام لایه ادغام، P برای نشان دادن لایه لایه جمعآوری، T برای نشان دادن تعداد دنبالههایی که باید به لایه RNN وارد کنیم، استفاده میکنیم. و W برای نشان دادن عرض ویژگی خروجی توسط لایه CNN، فرمول محاسبه K, S, P به شرح زیر است:$$begin{aligned} left{ begin{array}{lr} K = (1، CEIL(W/T))\ S = (1، CEIL(W/T))\ T_1 = (CEIL(W/K[19459036))\P=(0،FLOOR((K[1]*T_1 – W +1)/2)) end{آرایه} راست. end{aligned}$$
نمودار معماری دقیق لایه RNN در شبکه CRNN-RES. به منظور حل مشکلات فوق، ساختاری طراحی کردیم که می تواند به طور انعطاف پذیر طول توالی داده های ورودی لایه RNN را برای داده های هدف مختلف پیکربندی کند. لایه اتصال انعطاف پذیر بین لایه CNN و RNN، ما آن را لایه CRFC می نامیم و ساختار آن به صورت پویا بر اساس ویژگی های خروجی لایه CNN تنظیم می شود. برای مواردی که طول دنباله کاراکتر هدف بسیار کوچکتر از عرض ویژگی خروجی است، ساختار آن در شکل 3 نشان داده شده است. فرآیند خاص به شرح زیر است: (الف) ویژگی های خروجی توسط لایه CNN هستند. به عملیات های ادغام و کاملا متصل تغذیه می شود، عرض W ویژگی به T تبدیل می شود و این دو اضافه می شوند. ما از K برای نشان دادن اندازه هسته لایه ادغام، S برای نشان دادن اندازه گام لایه ادغام، P برای نشان دادن لایه لایه جمعآوری، T برای نشان دادن تعداد دنبالههایی که باید به لایه RNN وارد کنیم، استفاده میکنیم. و W برای نشان دادن عرض ویژگی خروجی توسط لایه CNN، فرمول محاسبه K, S, P به شرح زیر است:$$begin{aligned} left{ begin{array}{lr} K = (1، CEIL(W/T))\ S = (1، CEIL(W/T))\ T_1 = (CEIL(W/K[19459036))\P=(0،FLOOR((K[1]*T_1 – W +1)/2)) end{آرایه} راست. end{aligned}$$
(13)
جایی که (T_1) تعداد دنبالههای نهایی دادهای را نشان میدهد که در نهایت به دست میآوریم و باید در لایه RNN وارد کنیم. ساختار این لایه در شکل 4 نشان داده شده است، جایی که B نشان دهنده اندازه دسته، C تعداد کانال، H و W به ترتیب ارتفاع و عرض ویژگی، و T نشان دهنده تعداد دنباله است. وقتی طول دنباله کاراکتر هدف بیشتر از عرض ویژگی خروجی باشد، CNN مستقیماً از اتصال کامل برای تبدیل عرض ویژگی از W به T استفاده میکند، ساختار در شکل 5 نشان داده شده است. شکل 4 ساختار لایه همگرایی انعطاف پذیر CNN و RNN. از آنجایی که لایه pooling وابسته به مکان و لایه اتصال کامل مستقل از مکان است، به منظور ادغام ویژگی های وابسته به مکان و مستقل از مکان، از ادغام و اتصال کامل به صورت موازی استفاده می کنیم. شکل 5
ساختار لایه همگرایی انعطاف پذیر CNN و RNN. از آنجایی که لایه pooling وابسته به مکان و لایه اتصال کامل مستقل از مکان است، به منظور ادغام ویژگی های وابسته به مکان و مستقل از مکان، از ادغام و اتصال کامل به صورت موازی استفاده می کنیم. شکل 5 زمانی که طول دنباله کاراکتر هدف بیشتر از عرض ویژگی خروجی است، CNN مستقیماً از اتصال کامل برای تبدیل عرض ویژگی از W به T استفاده می کند. تغییرات لایه پیچیدگی به منظور بهبود اثر تشخیص کاراکترهای باریک، لایه ادغام CRNN اصلی از یک هسته ادغام باریک استفاده می کند، اما این هسته ادغام کاراکترهای گسترده را در نظر نمی گیرد. در داده های واقعی، کاراکترهای باریک و کاراکترهای گسترده با هم وجود دارند. علاوه بر این، برای اینکه شبکه قابلیت استخراج ویژگی قویتری داشته باشد، لایه CNN را بهبود میبخشیم. لایه کانولوشن CRNN-RES برای استخراج اطلاعات ویژگی تصویر استفاده می شود که می تواند به عنوان لایه استخراج ویژگی شبکه در نظر گرفته شود. هدف از اصلاح ما در شبکه کانولوشن این است که شبکه قابلیت استخراج ویژگی های قوی تری داشته باشد و اطمینان حاصل شود که هر لایه کانولوشن می تواند اطلاعات ویژگی های تصویر غنی تری را استخراج کند. همانطور که از شکل 4 می بینید، در مقایسه با شبکه کانولوشن CRNN، ما یک لایه BatchNomalization13 را بعد از لایه سوم کانولوشن اضافه کردیم تا شبکه را بهتر با ویژگی های کانولوشن تطبیق دهیم. تصویر، احتمال اینکه ویژگیها بیش از حد پیچیده هستند و از قابلیت اتصال شبکه فراتر میروند را کاهش میدهد. پس از پیچیدگی لایه اول و لایه دوم، به ترتیب یک لایه ترکیبی با اندازه هسته (1times 2) اضافه شد و نتایج خروجی لایه تلفیقی با اندازه هسته اضافه شد. از (2times 2) با لایههای ترکیبی با اندازه هسته (1times 2) ترکیب شدند. هدف این است که به شبکه اجازه داده شود از چندین فیلد گیرنده برای استخراج ویژگیها استفاده کند، قابلیتهای استخراج ویژگی شبکه را افزایش دهد، و شبکه قابلیتهای استخراج ویژگی بهتری برای کاراکترهای گسترده و کاراکترهای باریک داشته باشد. در دو لایه اخیر، لایه ادغام را به ترتیب با اندازه هسته (3times 2) اضافه کردیم و نتایج خروجی لایه تلفیقی را با اندازه هسته ترکیب کردیم. (1times 2) و نتایج خروجی لایه ادغام با اندازه هسته (3times 2). هدف در اینجا این است که شبکه از چندین فیلد گیرنده برای استخراج ویژگیها استفاده کند تا شبکه برای کاراکترهای گسترده و کاراکترهای باریک دوستانه باشد. هدف از افزودن لایه های تلفیقی به دست آوردن میدان های دریافتی مختلف و ویژگی های میدان پذیرای بیشتر است. به این ترتیب، شبکه بهتر میتواند ویژگیهای کاراکترهای باریک و کاراکترهای گسترده را استخراج کند تا دقت تشخیص کاراکترهای با اندازههای مختلف بهبود یابد. به منظور تسهیل درک خواننده، از جبر و نمودارها برای نشان دادن تغییرات خود استفاده میکنیم. لایه کانولوشنال: فرض کنید که نتیجه حداکثر شاخه ادغام شده 1 A و نتیجه ماکزیمم شاخه ادغام شده 2 M است. سپس نتیجه نهایی P توسط لایه ادغام بدست می آید:$$begin{aligned} P = A + M end{تراز شده}$$
زمانی که طول دنباله کاراکتر هدف بیشتر از عرض ویژگی خروجی است، CNN مستقیماً از اتصال کامل برای تبدیل عرض ویژگی از W به T استفاده می کند. تغییرات لایه پیچیدگی به منظور بهبود اثر تشخیص کاراکترهای باریک، لایه ادغام CRNN اصلی از یک هسته ادغام باریک استفاده می کند، اما این هسته ادغام کاراکترهای گسترده را در نظر نمی گیرد. در داده های واقعی، کاراکترهای باریک و کاراکترهای گسترده با هم وجود دارند. علاوه بر این، برای اینکه شبکه قابلیت استخراج ویژگی قویتری داشته باشد، لایه CNN را بهبود میبخشیم. لایه کانولوشن CRNN-RES برای استخراج اطلاعات ویژگی تصویر استفاده می شود که می تواند به عنوان لایه استخراج ویژگی شبکه در نظر گرفته شود. هدف از اصلاح ما در شبکه کانولوشن این است که شبکه قابلیت استخراج ویژگی های قوی تری داشته باشد و اطمینان حاصل شود که هر لایه کانولوشن می تواند اطلاعات ویژگی های تصویر غنی تری را استخراج کند. همانطور که از شکل 4 می بینید، در مقایسه با شبکه کانولوشن CRNN، ما یک لایه BatchNomalization13 را بعد از لایه سوم کانولوشن اضافه کردیم تا شبکه را بهتر با ویژگی های کانولوشن تطبیق دهیم. تصویر، احتمال اینکه ویژگیها بیش از حد پیچیده هستند و از قابلیت اتصال شبکه فراتر میروند را کاهش میدهد. پس از پیچیدگی لایه اول و لایه دوم، به ترتیب یک لایه ترکیبی با اندازه هسته (1times 2) اضافه شد و نتایج خروجی لایه تلفیقی با اندازه هسته اضافه شد. از (2times 2) با لایههای ترکیبی با اندازه هسته (1times 2) ترکیب شدند. هدف این است که به شبکه اجازه داده شود از چندین فیلد گیرنده برای استخراج ویژگیها استفاده کند، قابلیتهای استخراج ویژگی شبکه را افزایش دهد، و شبکه قابلیتهای استخراج ویژگی بهتری برای کاراکترهای گسترده و کاراکترهای باریک داشته باشد. در دو لایه اخیر، لایه ادغام را به ترتیب با اندازه هسته (3times 2) اضافه کردیم و نتایج خروجی لایه تلفیقی را با اندازه هسته ترکیب کردیم. (1times 2) و نتایج خروجی لایه ادغام با اندازه هسته (3times 2). هدف در اینجا این است که شبکه از چندین فیلد گیرنده برای استخراج ویژگیها استفاده کند تا شبکه برای کاراکترهای گسترده و کاراکترهای باریک دوستانه باشد. هدف از افزودن لایه های تلفیقی به دست آوردن میدان های دریافتی مختلف و ویژگی های میدان پذیرای بیشتر است. به این ترتیب، شبکه بهتر میتواند ویژگیهای کاراکترهای باریک و کاراکترهای گسترده را استخراج کند تا دقت تشخیص کاراکترهای با اندازههای مختلف بهبود یابد. به منظور تسهیل درک خواننده، از جبر و نمودارها برای نشان دادن تغییرات خود استفاده میکنیم. لایه کانولوشنال: فرض کنید که نتیجه حداکثر شاخه ادغام شده 1 A و نتیجه ماکزیمم شاخه ادغام شده 2 M است. سپس نتیجه نهایی P توسط لایه ادغام بدست می آید:$$begin{aligned} P = A + M end{تراز شده}$$
(14)
تغییرات ما در ماژول CNN در جدول 1 زیر نشان داده شده است. خوانندگان می توانند برای درک ساختار دقیق و پارامترهای شبکه CNN-RES به جدول 1 زیر مراجعه کنند. از طریق جدول 1 زیر، خوانندگان به راحتی می توانند با جزئیات نحوه اضافه کردن لایه عادی سازی دسته ای (BN)13 و دلیل اصلاح لایه ادغام را درک کنند. هیچ تغییری در ماژول CNN وجود ندارد به جز اضافه کردن یک لایه عادی سازی دسته ای و لایه های ادغام. ساختار شبکه دقیق ماژول CNN در جدول 1 و معماری لایه CNN CRNN-RES در شکل 6 نشان داده شده است. جدول 1 ساختار شبکه تنظیمات CNN.
شکل 6  معماری لایه CNN CRNN-RES.
معماری لایه CNN CRNN-RES.
یک شبکه نوآورانه مبتنی بر میدان دریافتی دوگانه و حافظه کوتاه مدت دو جهته بازگشتی
